
From Netflix to Gmail: 10 Machine Learning Algorithms That Make Your Life Easier
Imagine teaching a child to recognize animals. Instead of listing rules, you would show them pictures until they learn patterns on their own. That’s the essence of machine learning. Now, instead of programming every scenario, we feed computers data so they can identify patterns and make decisions. Once a model learns from this data, it can predict outcomes or categorize new information.
MACHINE LEARNING
By Brian Valencia
3/20/20256 min read
Machine Learning in Your Daily Life
A machine learning model is like a trained program that spots specific patterns. Its learning fuel? Tagged training data. By studying past information, it can predict future trends like forecasting scenarios based on previous trends.
Machine learning is behind many everyday activities, including:
Facial recognition: Unlocking your phone with a glance.
Personalized recommendations: Suggesting movies, music, and products.
Spam filters: Keeping unwanted emails out of your inbox.
Virtual assistants: Answering questions and automating tasks.
Fraud detection: Identifying suspicious transactions in banking.
These algorithms work in the background, making technology smarter and more efficient.
Diving into the Algorithms
Now, let's explore some of the most common machine learning algorithms that play a significant role in our daily interactions with technology.
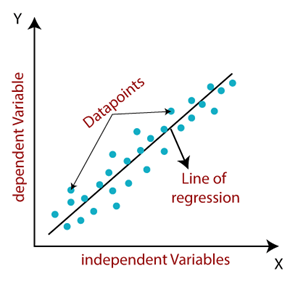
1. Linear regression
What's the Goal? Linear regression is a fundamental algorithm used to predict the relationship between two or more variables by fitting a linear equation to the observed data. Its primary objective is to find the straight line that best represents how one variable (the dependent variable in axis Y) changes in relation to one or more other variables (the independent variables in axis X).
Everyday Examples:
Prediction: Predicting values of a dependent variable based
on known values of independent variables.
Trend Analysis: Identifying and understanding trends in data.
Forecasting: Predicting future values based on past data
(with linear behavior)
Source: tpointtech.com
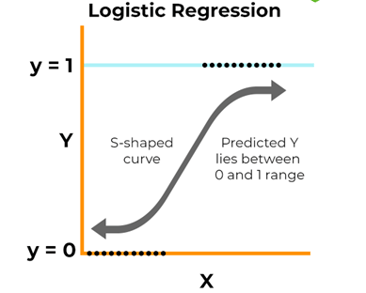
2. Logistic Regression
What's the Goal? Logistic regression is a powerful algorithm used to estimate the probability of a binary outcome, meaning an outcome with only two possible values, such as yes/no, true/false, or 0/1 . Unlike linear regression, which predicts a continuous value, logistic regression is primarily used for classification tasks where the goal is to categorize data into one of two distinct classes.
Everyday Examples:
Marketing: Predicting customer churn or purchase likelihood.
Finance: Identifying fraudulent transactions.
Healthcare: Diagnosing diseases or predicting patient outcomes.
Source: spiceworks.com
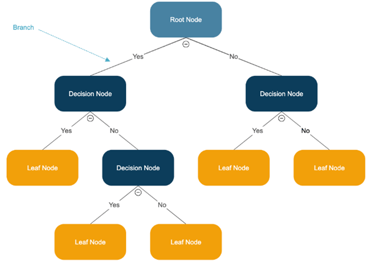
3. Decision Trees
What's the Goal? Decision trees are a versatile algorithm that creates a tree-like structure to classify or predict an outcome based on a series of rules. Think of it as a flowchart where each internal node represents a decision or a test on an attribute, each branch represents the outcome of that test, and each leaf node represents the final decision or prediction.
Everyday Examples:
Healthcare: Doctors might implicitly use a decision tree
approach when diagnosing a patient.
Finance: Banks use decision trees to decide whether
to approve a loan application.
Source:SmartDraw
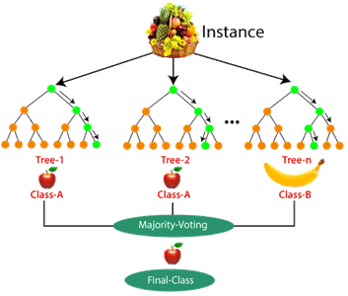
4. Random Forest
What's the Goal? Random forest is an ensemble learning algorithm that aims to improve the accuracy and robustness of decision trees by creating a "forest" of multiple decision trees and aggregating their predictions.
Everyday Examples:
E-commerce: Random forests can analyze customer purchase
history and browsing patterns to provide personalized
product recommendations.
Image and Text Classification: Random forests can be
used to classify images and text data, for example,
identifying objects in images or classifying documents by topic.
Healthcare: Random forests can analyze patient data,
including medical history and test results, to assist in
diagnosing diseases.
Source: Medium
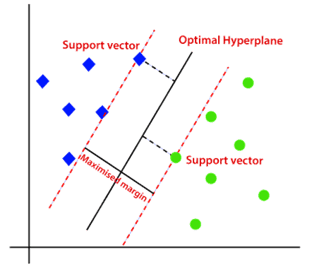
5. Support Vector Machines (SVM)
What's the Goal? Support Vector Machines (SVM) are a powerful supervised learning algorithm primarily used for classification tasks. The fundamental goal of an SVM is to find an optimal hyperplane, which is a line (in two dimensions) or a surface (in higher dimensions), that best separates different classes of data points in a high-dimensional space.
Everyday Examples:
Image Classification: SVMs are often used in image recognition
applications, such as identifying whether an image contains
a cat or a dog.
Text Classification and Sentiment Analysis: SVMs can be
employed to categorize text documents, such as news
articles or customer reviews, into different topics.
Medical Diagnosis: SVM is used in medical diagnosis to classify
diseases, such as cancer, based on patient symptoms and test results.
Source: tpointtech.com
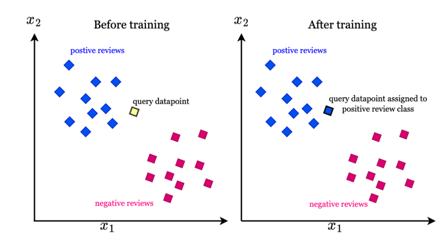
6. K-Nearest Neighbors (KNN)
What's the Goal? The K-Nearest Neighbors (KNN) algorithm is a simple, yet effective supervised learning algorithm used for both classification and regression tasks. Its fundamental principle is that similar data points tend to be close to each other in a feature space.
Everyday Examples:
Recommendation Systems: Identifies users with
similar preferences and recommends content or
products they might enjoy (Like Netflix or Amazon
recommending movies to you).
Image and Document Similarity: Can group images
based on similarity, useful for tasks like facial recognition
or object detection.
Healthcare: Can analyze patient data and identify
similar cases to predict diseases or assist in diagnosis.
Source: intuitivetutorial.com
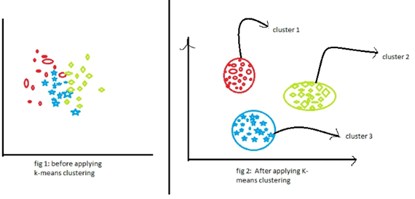
7. K-Means Clustering
What's the Goal? K-means clustering is an unsupervised learning algorithm that aims to group a set of unlabeled data points into 'k' clusters. Here, 'k' is a number specified by the user, representing the desired number of clusters. The algorithm works by iteratively assigning each data point to the cluster whose centroid is nearest.
Everyday Examples:
Business: Businesses use K-means to group customers with
similar buying behaviors, preferences, or demographics to
personalize marketing campaigns and product recommendations.
Data Analysis:
Face Detection: Recognizing faces in an image by
clustering pixels based on their features
Spam Detection: Spotting patterns in emails to classify
them as spam or legitimate.
Source: analyticsvidhya.com
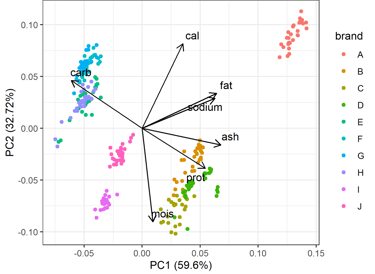
8. Principal Component Analysis (PCA)
What's the Goal? Principal Component Analysis (PCA) is a dimensionality reduction technique used to simplify large datasets by transforming the original variables into a smaller set of new, uncorrelated variables called principal components
Everyday Examples:
Image Compression: Techniques like PCA are used in image
compression formats like JPEG.
Stock Market Analysis: PCA can be applied to analyze the
movements of many different stocks.
Data simplification: simplify the complexity in high
dimensional data while retaining trends and patterns
Source: statisticsglobe.com
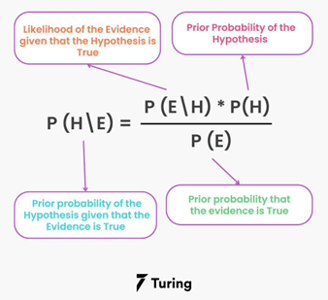
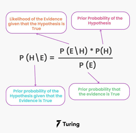
9. Naive Bayes
What's the Goal? Naive Bayes is a simple and widely used supervised learning algorithm for classification tasks, particularly in text classification. It's based on Bayes' Theorem, a fundamental concept in probability theory, and it makes a rather "naive" assumption that all the variables in the dataset are conditionally independent of each other given the class label.
Everyday Examples:
Sentiment Analysis: Naive Bayes can be used to analyze
the sentiment expressed in text, such as customer reviews
or social media posts
Document Classification: This algorithm is also effective
for categorizing documents or news into different topics.
Source: turing.com
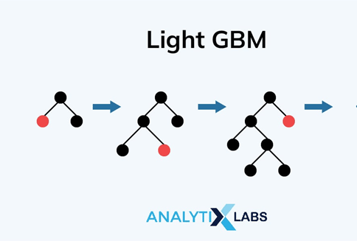
10. Gradient Boosting
What's the Goal? Gradient Boosting in Machine Learning is to sequentially build a strong predictive model by combining multiple weak models (typically decision trees) to minimize errors and improve accuracy. Unlike traditional ensemble methods, Gradient Boosting works by learning from the mistakes of previous models, adjusting weights, and optimizing predictions in each step.
Everyday Examples:
Search Engine Ranking: Gradient boosting is used by search
engines like Google to rank web pages based on their
relevance to a search query.
Predicting Customer Churn: Businesses can employ gradient
boosting to predict which customers are likely to stop
using their services.
Fraud Detection in Finance: Financial institutions utilize
gradient boosting to detect fraudulent transactions.
By analyzing patterns in past transactions, the algorithm
can identify suspicious activities and flag them for
further investigation.
Source: analytixlabs.co.in



Below is a table showing the 10 most commonly used machine learning algorithms along with their core mathematical expressions, R code examples, and Python code examples. Note that the library choices may vary depending on your specific needs, so always double-check your implementation.