De Netflix a Gmail: 10 algoritmos de aprendizaje automático que facilitan tu vida
Imagina enseñar a un niño a reconocer animales. En lugar de enumerar reglas, le mostrarías imágenes hasta que aprenda los patrones por sí mismo. Esa es la esencia del aprendizaje automático o machine learning. Ahora, en lugar de programar cada escenario, alimentamos a las computadoras con datos para que puedan identificar patrones y tomar decisiones. Una vez que un modelo aprende de estos datos, puede predecir resultados o categorizar nueva información.
MACHINE LEARNING
Por Brian Valencia
3/20/20255 min leer
Aprendizaje automático en tu vida diaria
Un modelo de aprendizaje automático es como un programa entrenado que detecta patrones específicos. ¿Su combustible? Datos etiquetados. Al estudiar información pasada, puede predecir tendencias futuras, como pronosticar escenarios basados en tendencias previas.
El aprendizaje automático está detrás de muchas actividades cotidianas, entre ellas:
Reconocimiento facial: Desbloquear tu teléfono con una mirada.
Recomendaciones personalizadas: Sugerir películas, música y productos.
Filtros de spam: Mantener fuera de tu bandeja de entrada correos no deseados.
Asistentes virtuales: Responder preguntas y automatizar tareas.
Detección de fraudes: Identificar transacciones sospechosas en la banca.
Estos algoritmos trabajan en segundo plano, haciendo la tecnología más inteligente y eficiente.
Profundizando en los algoritmos
Ahora, exploremos algunos de los algoritmos de aprendizaje automático más comunes que juegan un papel importante en nuestras interacciones diarias con la tecnología.
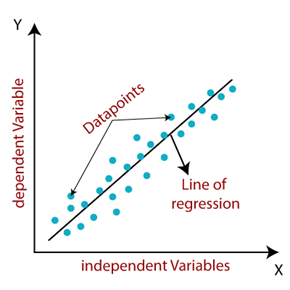
1. Regresión lineal
¿Cuál es el objetivo?
La regresión lineal es un algoritmo básico que se utiliza para predecir la relación entre dos o más variables ajustando una ecuación lineal a los datos observados. Su objetivo es encontrar la línea recta que mejor representa cómo cambia una variable (la dependiente en el eje Y) en relación a una o más variables independientes (en el eje X).
Ejemplos cotidianos:
Predicción: Predecir valores de una variable dependiente
según valores conocidos de variables independientes.
Análisis de tendencias: Identificar y entender
tendencias en los datos.
Pronósticos: Predecir valores futuros basados en
datos pasados (con comportamiento lineal).
Fuente: tpointtech.com
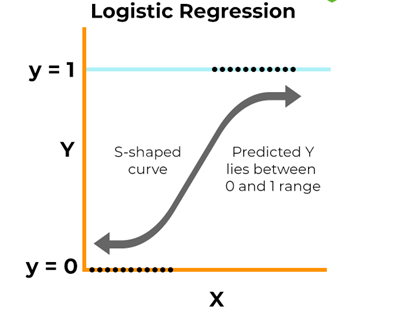
2. Regresión logística
¿Cuál es el objetivo?
La regresión logística se usa para estimar la probabilidad de un resultado binario (sí/no, verdadero/falso, 0/1). A diferencia de la regresión lineal, que predice un valor continuo, la regresión logística se utiliza para clasificar los datos en dos categorías.
Ejemplos cotidianos:
Marketing: Predecir la pérdida de clientes o la
probabilidad de compra.
Finanzas: Identificar transacciones fraudulentas.
Salud: Diagnosticar enfermedades o predecir
resultados en pacientes.
Fuente: spiceworks.com
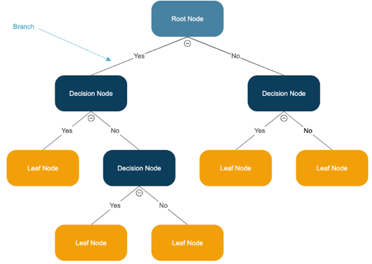
3. Árboles de decisión
¿Cuál es el objetivo?
Los árboles de decisión crean una estructura similar a un diagrama de flujo para clasificar o predecir un resultado mediante una serie de reglas. Cada nodo interno es una decisión, cada rama es el resultado de esa decisión y cada hoja es la predicción final.
Ejemplos cotidianos:
Salud: Los médicos pueden usar un enfoque similar
al de un árbol de decisión al diagnosticar a un paciente.
Finanzas: Los bancos usan árboles de decisión para
decidir si aprueban una solicitud de préstamo.
Fuente: SmartDraw
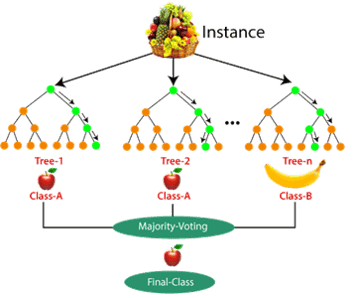
4. Random Forest
¿Cuál es el objetivo?
El bosque aleatorio es un algoritmo que mejora la precisión de los árboles de decisión creando un "bosque" de múltiples árboles y combinando sus predicciones.
Ejemplos cotidianos:
Comercio electrónico: Analiza el historial de compras y
patrones de navegación para ofrecer recomendaciones
personalizadas.
Clasificación de imágenes y textos: Clasifica imágenes
y documentos, por ejemplo, para identificar objetos o temas.
Salud: Ayuda a diagnosticar enfermedades analizando
datos de pacientes.
Fuente: Medium
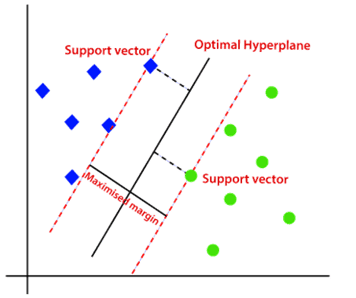
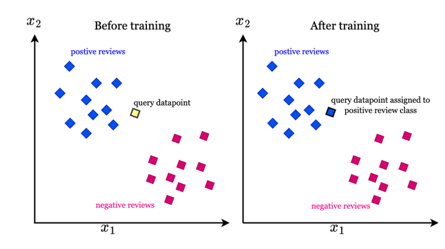
5. Support vector machine (SVM)
¿Cuál es el objetivo?
Las SVM son un algoritmo supervisado para tareas de clasificación. Su meta es encontrar un hiperplano óptimo que separe las diferentes clases de datos en un espacio de alta dimensión.
Ejemplos cotidianos:
Clasificación de imágenes: Identificar si una imagen
contiene un gato o un perro.
Análisis de textos y sentimientos: Categorizar documentos
o reseñas en distintos temas.
Diagnóstico médico: Clasificar enfermedades, como el cáncer,
basándose en síntomas y pruebas.
Fuente: tpointtech.com
6. K-Vecinos más Cercanos (KNN)
¿Cuál es el objetivo?
El algoritmo KNN es simple y efectivo para clasificación y regresión. Se basa en la idea de que los datos similares se encuentran cerca en el espacio de características.
Ejemplos cotidianos:
Sistemas de recomendación: Encuentra usuarios con gustos
similares y sugiere contenido o productos (como Netflix o Amazon).
Similitud de imágenes y documentos: Agrupa imágenes
según su parecido, útil en reconocimiento facial.
Salud: Identifica casos similares en datos de pacientes
para predecir enfermedades o ayudar en el diagnóstico.
Fuente: intuitivetutorial.com
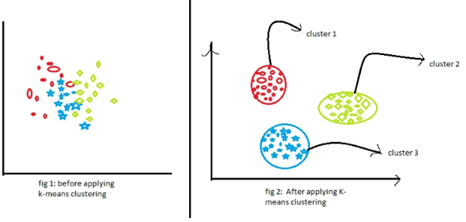
7. Agrupamiento K-means
¿Cuál es el objetivo?
K-means es un algoritmo no supervisado que agrupa datos no etiquetados en "k" clústeres, asignando cada dato al grupo cuyo centroide es el más cercano.
Ejemplos cotidianos:
Negocios: Agrupa clientes con comportamientos o preferencias
similares para personalizar campañas de marketing.
Análisis de datos: Descubre patrones agrupando datos.
Detección de rostros: Reconoce rostros en imágenes
agrupando píxeles.
Detección de spam: Clasifica correos como spam o
legítimos basándose en patrones.
Fuente: analyticsvidhya.com
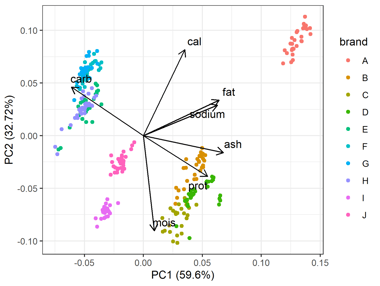
8. Análisis de Componentes Principales (PCA)
¿Cuál es el objetivo?
PCA es una técnica de reducción de dimensiones que simplifica grandes conjuntos de datos transformando las variables originales en un conjunto menor de componentes principales no correlacionados.
Ejemplos cotidianos:
Compresión de imágenes: Utilizado en formatos como JPEG.
Análisis bursátil: Ayuda a analizar el movimiento de muchas acciones.
Simplificación de datos: Reduce la complejidad manteniendo tendencias
y patrones.
Fuente: statisticsglobe.com
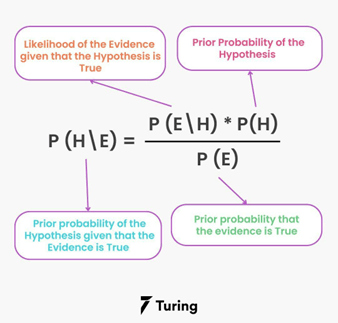
9. Naive Bayes
¿Cuál es el objetivo?
Naive Bayes es un algoritmo simple y popular para clasificación, especialmente en textos. Se basa en el Teorema de Bayes y asume que todas las variables son independientes dadas las etiquetas de clase.
Ejemplos cotidianos:
Análisis de sentimientos: Analiza el sentimiento en reseñas o
publicaciones en redes sociales.
Clasificación de documentos: Categoriza noticias o
documentos en diferentes temas.
Fuente: turing.com
10. Gradient Boosting
¿Cuál es el objetivo?
Gradient Boosting construye un modelo predictivo fuerte combinando múltiples modelos débiles (generalmente árboles de decisión) para minimizar errores y mejorar la precisión. Aprende de los errores anteriores ajustando pesos en cada paso.
Ejemplos cotidianos:
Posicionamiento en buscadores: Se utiliza en motores como
Google para clasificar páginas web según su relevancia.
Predicción de pérdida de clientes: Predice qué clientes
pueden dejar de usar un servicio.
Detección de fraudes: Ayuda a identificar transacciones
sospechosas en el sector financiero.
Fuente: analytixlabs.co.in
A continuación se muestra una tabla con los 10 algoritmos de aprendizaje automático más utilizados, junto con sus expresiones matemáticas básicas, ejemplos de código en R y ejemplos de código en Python. Ten en cuenta que la elección de librerías puede variar según tus necesidades específicas, así que siempre verifica la implementación.